Data scientist 를 준비하면서 직접 받았던 인터뷰 질문이나, 인터넷에서 찾을 수 있는 질문들을 모아서 꾸준히 답안지를 작성해 보려합니다. 잘못된 정보가 있거나 필요한 질문이 있으면 편하게 알려주세요.
질문출처:https://zzsza.github.io/data/2018/02/17/datascience-interivew-questions/#contents
https://www.simplilearn.com/tutorials/data-science-tutorial/data-science-interview-questions
Top 50 Data Science Interview Questions and Answers 2022 | Simplilearn
Uncover the top Data Science interview questions from basic to technical that will help you prepare for your interview and crack it in first attempt!
www.simplilearn.com
데이터 사이언스 인터뷰 질문 모음집
데이터 사이언스 분야의 인터뷰 질문을 모아봤습니다. (데이터 분석가 / 데이터 사이언티스트 / 데이터 엔지니어) 구직자에겐 예상 질문을 통해 면접 합격을 할 수 있도록, 면접관에겐 좋은 면접
zzsza.github.io
Q1. Supervised-Learning과 Unsupervised-Learning 차이 (지도 비지도학습)
A) 지도 학습의 경우 사람이 직접 데이터를 보고 label 을 하며 모델에게 feedback 을 줍니다. 반대로 비지도 학습의 경우 따로 label 을 하지않으며 사람이 직접 모델이게 feedback 을 주지않습니다.
Q2. Decision Tree Algorithm 에 대해서 얘기해주세요.
A) 지도 학습의 종류 중 하나이며 Regression classification 등을 사용할때 쓰입니다. 데이터 종류에 상관없이 사용할수 있는 알고리즘 이며 (categorical and numerical) 데이터를 작은 데이터로 작은단위로 쪼개가며 특징을 찾아내는것이 특징입니다.
Q3. Bias란?
A) Bias 란 모델을 학습시킬때 학습이 충분히 되지않거나 oversimplification때문에 생기는 error 입니다. Underfitting의 원인이 될 수 있습니다.
Q4. Ensemble Learning (앙상블)이란?
A) 앙상블이란 여러가지 모델이나 학습방법을 합쳐서 모델의 안정성이나 정확도를 높이는 작업을 말합니다. 예를 들어, Random Forest, XGBoost, Neural Network 등등의 모델로 결과를 도출해 낸 후 세가지 결과를 합쳐서 Regression 모델을 적용시키는 방법이 있습니다.
Q5. Naive Bayes algorithm란?
A) Naive Bayes algorithm 은 Bayes Theorem 에 기반을 두고 있으며, 과거의 지식이나 데이터를 이용해서 새로운 이벤트를 예측하는 확률입니다.
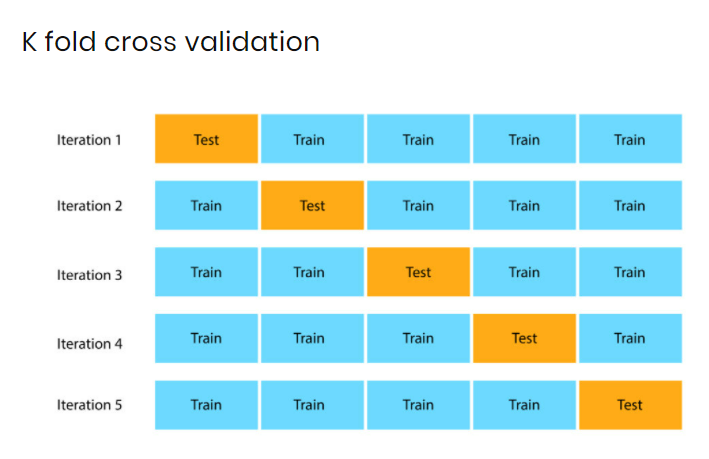
Q6. Cross Validation은 무엇이고 어떻게 해야하나요?
A) Cross-Validation 은 Train 과 Test 모델을 나눠 서로 교차하며 모델의 퍼포먼스를 비교하는 통계적 방법 입니다. 주로 제한된 데이터 셋에서 overfitting(과적합)을 막기 위해 사용됩니다. Cross Validation 을 하기위해선 먼저 Train / Test 셋을 섞은후 8:2 또는 7:3 비율로 나누고 모델의 성능을 비교합니다. 다른 방법으로는 iteration 별로 성능을 비교하는 k-fold cross validation 이 있습니다.
Q7) 회귀 / 분류시 (regression / classification) 알맞은 metric은 무엇일까요?
A) 먼저 regression model (회귀)는 연속된 수를 모델을 통해 예측 하는것이므로 모델의 예측값과 실제값으 오차가 존재하게 됩니다. 그리하여 알맞은 metric은 아래와 같습니다.
- Mean Squared Error (MSE) - 실제값(y)과 예측값(y-hat)을 뺀 후 제곱을 하게 됩니다. 그리하여 loss function 으로 사용됫을 경우 예측값과 실제값의 차이가 클수록 제곱이 되기 때문에 loss 가 커지게 됩니다.
- Root Mean Squared Error (RMSE) - MSE 에서 루트를 씌워준 값으로 outlier (이상치)에 민감하며 항상 양수로 나오게 됩니다.
- Mean Absolute Error (MAE) - MSE 와 RMSE과는 다르게 제곱을 하지 않기 때문에 실제값과의 오차가 커도 loss에 영향을 덜 받게 됩니다. 그러고 절대값을 사용하기 때문에 실제값과 예측값이 양수 음수 상관없이 양수로 계산을 하게 됩니다.
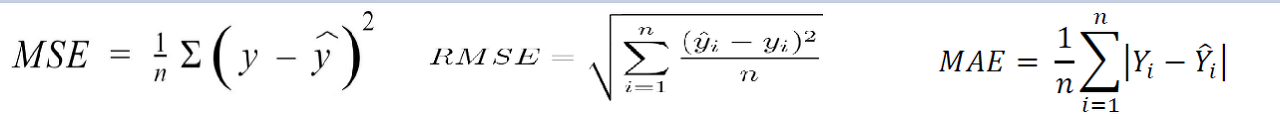
Classification 을 위한 metrics에는 아래와 같은 것들이 있습니다.
- Accuracy (정확도) = (TP+TN)/(TP+FP+FN+TN)
- Recall (재현율) = (TP)/(TP+FN)
- Precision (정밀도) = (TP)/(TP+FP)
F1-Score
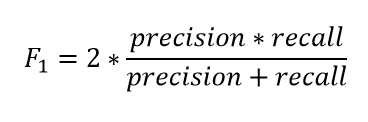
F1 Score 같은 경우 Precision 과 Recall 둘다 사용해서 weighted average 를 구하게 됩니다. 그리하여, false positive (FP) false negative (FN)을 사용한 특성을 가지게됩니다.
Log Loss / Binary Crossentropy

Categorical Crossentropy

Q8) L1(Lasso), L2(Ridge) 정규화란?
A) L1, L2 정규화는 딥러닝에서 보델의 overfitting 을 막기 위함으로 weight regularization 을 하고싶을 때 사용된다. L1와 L2는 굉장히 비슷하지만 중요한 차이점을 가진다. L1이랑 L2와의 가장 큰 차이점은 L1(Lasso) regression 은 slope 가 0 이 될 수 있지만 L2(Ridge)은 0에 가깝게만 근접할수 잇을뿐 0 이될수 없습니다.
L1 Regularization (lasso)
- 검증 데이터 셋의 검증력을 높이기 위해 bias 를 임의로 주는 방법을 말합니다.
Since Lasso Regression can exclude useless variables from equations, it is a little better than Ridge Regression at reducing the Variance in models THAT CONTAIN A LOT OF USELESS VARIABLES.
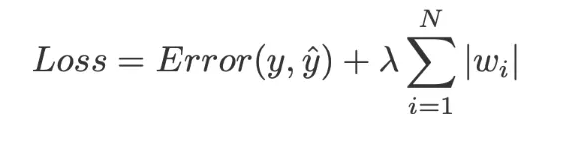
L2 Regularization (Ridge)
- The main indea behind Ridge Regression is to find a New Line that doesn't fit the Training Data as well. In other words, we introduce a small amount of Bias into how the New Line is fit to the data...but in return for that small amount of bias, we get a significant drop in Variance. worse fit can provide better long term predictions.
L2 Regularization = the sum of the squared residuals + lambda (slope)^2
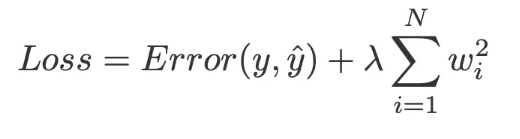
데이터가 적을때 training data 에 적합성을 낮춤으로 인해 테스트 셋의 장기 검증력을 높임.
'2. Data Science Basics > Python' 카테고리의 다른 글
| Dynamic Time Warping (DTW) (0) | 2022.03.02 |
|---|---|
| Python 을 이용하여 MDD / Sharp Ratio 구하기 (0) | 2022.01.03 |
| Reddit에서 코인뉴스 API로 크롤링하기 (0) | 2021.12.28 |
| A/B Testing 란? (0) | 2021.08.24 |
| 간단한 NLP 모델로 WSJ 부정적인 기사만 crawling 하기 (0) | 2021.08.23 |


댓글