시계열 데이터를 공부하다 보면 비슷하게 움직이거나 서로 관련이 있는 데이터들을 종종 볼 수가 있습니다.

예를 들어 주식시장 데이터에 빗대어 설명해 보면, 전염병에 민감한 주식인 항공주들 같은 경우 코로나 발생이후 급격히 떨어졌으며 계속 서로 비슷하게 움직이는걸 확인할 수 있습니다. 위 그래프는 미국의 대표 한공사인 American Airline 과 Delta Airline의 그래프입니다. 상당히 비슷하게 움직이는 것을 확인할 수 있고 같은 테마로 움직이는 시계열 데이터라고 볼 수 있습니다.
하지만 우리가 위와 같은 사전 정보가 없이 (AAL이랑 DAL이랑 비슷하게 움직이는것을 모르는채) 이러한 정보를 알아낼수 있는 방법을 가장 잘 나타낸 알고리즘중 하나가 Dynamic Time Warping (DTW) 입니다. 이번에는 DTW를 이용하여 비슷한 테마를 가진 주식을 찾아내서 clustering하는 방법을 알아보겠습니다.
먼저 모든 미국주식 종목을 위의 csv 파일을 다운받아주시고 필요한 라이브러리를 불러오겠습니다.
import yfinance as yf
import pandas as pd
import numpy as np
from tqdm import tqdm
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
import tslearn
from tslearn.metrics import dtwcompanies = pd.read_csv("../Documents/companies.csv")
companies.head(1)csv 파일에서 우리에게 필요한 ticker 만 불러 오겠습니다.
tickers = companies.ticker
len(tickers)약 6천개 조금 넘는 주식 종목들을 확인할 수 있습니다.
그 후, DTW 알고리즘을 사용하는 과정에서 직접 코딩을 하지않고 tslearn에 dtw을 계산해주는 알고리즘이 있어 사용하였습니다. StandardScaler 를 사용하여 주식가격들을 정규화해주었고 정규화 한 값이 임의값인 5보다 작거나 20보다 크면 list에 append 하도록 만들었습니다. (직접 해보시면 7보다 작은 종목들은 주로 비슷하게 움직이고 20보다 크면 완전 반대로 움직이는 성향이 있어서 유의미한 데이터를 찾아보기위해 둘다 append 해보았습니다)
def getDTW(data):
for i in range(1, len(data.T)):
#scale to fit
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
dtw = tslearn.metrics.dtw(data_scaled.T[0], data_scaled.T[i])
if dtw < 5 and dtw != float('inf'):
dtw_list.append([data.T.index[i], dtw])
elif dtw > 20 and dtw != float('inf'):
dtw_list.append([data.T.index[i], dtw])
return dtw_list
주식데이터를 얻어올때 편리한 yahoo finance 라이브러리를 사용하여 임의로 8개씩 pandas dataframe을 생성한 후 dtw를 계산하게 만들어 보았습니다. 너무 많은 주식을 한번에 비교하면 정확도가 떨어질수 있어서 8개씩 끊어 보았습니다.
i=0
global dtw_list
dtw_list = []
while True:
stock = 'AAL'
stock = yf.Ticker(stock).history(period='12mo')
for ticker in tqdm(tickers[i:i+8]):
try:
stock[ticker] = yf.Ticker(ticker).history(period='12mo')['Close']
except:
print("Error while importing {}".format(ticker))
stock.fillna(method='ffill', inplace=True)
stock.drop(['Open','High','Low','Volume','Dividends','Stock Splits'], axis=1, inplace=True)
getDTW(stock)
i += 8
print('{} out of {}'.format(int(i/8), int(len(tickers)/8)))
if int(i/8) > int(len(tickers)/8):
breakprint(dtw_list)결과값들이 나왔습니다. 오른쪽의 숫자가 낮을수록 유의미하게 비슷한 성향을 가지는 시계열 데이터 인것이고, 높을수록 그 반대가 되겠습니다. 좀 더 보기 편하게 dtw값이 낮은것부터 높은순으로 sort 한후 첫 5개의 데이터를 그려보았습니다. (AAL은 완전 같은 값을 가지고 있어서 0.0 이 계산되었고 당연히 제외하고 두번째 UAL 부터 그래프로 그려보았습니다.)
columnIndex = 1
temp = np.array(dtw_list)
sortedArr = temp[temp[:,columnIndex].astype(np.float).argsort()]
print('Sorted 2D Numpy Array')
print(sortedArr)
from plotly.subplots import make_subplots
import plotly.graph_objects as go
stock1 = 'AAL'
stock2 = 'UAL'
graph1 = yf.Ticker(stock1).history(period='12mo')
graph2 = yf.Ticker(stock2).history(period='12mo')
fig2 = make_subplots(specs=[[{"secondary_y": True}]])
fig2.add_trace(go.Scatter(x=graph1.index,y=graph1['Close'],name=stock1),secondary_y=False)
fig2.add_trace(go.Scatter(x=graph1.index,y=graph2['Close'],name=stock2),secondary_y=True)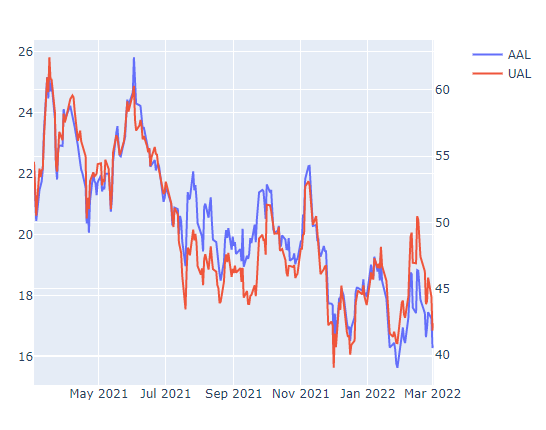

꽤나 유의미하게 결과가 나온것을 확인 할 수 있습니다. Dynamic Time Warping 은 주식데이터 한정이 아닌 시계열데이터, 음성데이터, 영상데이터등을 처리할때 다양하게 쓰일 수 있습니다. 감사합니다.
'2. Data Science Basics > Python' 카테고리의 다른 글
| 데이콘 쇼핑몰 지점별 매출액 예측 경진대회 (TOP 10%) (0) | 2022.08.08 |
|---|---|
| [논문분석] 머신러닝에서 유의미한 Feature 쉽게 구분해내기 (0) | 2022.05.30 |
| Dynamic Time Warping (DTW) (0) | 2022.03.02 |
| Python 을 이용하여 MDD / Sharp Ratio 구하기 (0) | 2022.01.03 |
| Data Science 인터뷰 질문 및 답변 (작성중) (0) | 2022.01.03 |



댓글