오늘은 재밌는 논문을 발견하여, 내용을 정리해보고 모델을 알아볼까 한다. 아래 논문은 내가 요즘 관심있게 공부하고있는 심리와 금융과 연관이 있기 때문에 좀 더 흥미롭게 느껴진다.
social media 이용자가 급증하면서, 약 34억명이 인터넷을 이용하였고 (2016년 기준) 그중 23억명이 소셜미디어 플랫폼을 이용하였다. 그 말은 곧 소셜미디어가 혁신적인 트렌드를 반영한다는 것은 부정할 수 없는 사실이 되었다. 그리하여, 대표적인 몇몇 온라인 플렛폼을 이용하여 금융이벤트들을 예측해 보려한다. 이 글에서 유가(WTI)를 예측하기 위해 사용한 매체는 다음과 같다: (1) Twitter (2) Wikipedia (3) Google Trends (4) GDELT Project. 이 와 같은 사이트에서 유가를 직접적으로 예측하는 것이 아닌, behavior & general attitude 를 관찰한 후 유가와의 상관관계를 찾아보는 것이다.
예로부터 금융시장을 예측하기위해 Quantitative approach 는 많이 해왔다. 하지만 요즘 데이터가 많아지고 인공지능 모델들이 발전하면서 text mining 기법도 사용하게 되었고 금융시장을 예측하는데 쓰이는 모델들은 다양하지만, 결과는 대략적으로 아래와 같다.
- linear models 은 volatility를 짧은 기간 예측하는데 유용했다 (1일)
- Nonlinear models 은 좀 더 긴 기간을 예측하는데 유용했다 (5-25일)
- non-seasonal ARIMA model 이 짧은 기간을 예측할땐 ANN(Artificial Nerual Networks) & SVM(Support Vector Machine)을 out perform 하지만, SVM이 긴 기간을 예측할땐 더 정확했다.
- 하지만 위 모델들의 overall performance 는 기대에 미치지 못하였고 효과적으로 예측을 해주지 못했다.
이 페이퍼에서는 ARIMAX 와 text mining 기법을 이용하여 econometric 과 computational techniques 를 적용하였다.
Hypotheses Formulation
이 실험의 가정은 아래와 같다
<가정>
H1a: The daily count of tweets is negatively related with oil price
H1b: The more positive the sentiment of the langauge of the tweets, the higher the oil price.
H1c: High emotionality values of twitter feeds are negatively related with oil price.
H1d: High complexity values of twitter feeds are negatively related with oil price.
H2: The query counts on Google Trends for terms "Price of Oil" and "Open" are positively related with oil price.
More counts mean higher prices.
H3: The page views count of the specialized Wikipedia articles "price of Oil" and "OPEC" are negatively related with oil price.
H4a: A higher number of articles on GDELT, for the search query “WTI Crude Oil Price”, is negatively related with oil price.
H4b: The number of organizations names mentioned on GDELT, with regard to the search query “WTI Crude Oil Price”, is positively related with the oil price.
<방법>
Description of Variables

트위터에서는 quantatative variable 들만 추출한 것 이 아닌, sentiment, emotionality, complexity 도 추출하였다.
나머지 variable 들은 대부분 quantatative 한 것들이다.
정확도 검증을 위해서는 Root Mean Squared Error(RMSE) 와 Mean Absolute Percentage Error(MAPE) 가 사용되었다.
<결과>
미래의 t 시간의 유가를 유측하기 위해 (t-n) 의 시간을 이용한다. (n = # of lags)
예를 들어, 금요일의 유가를 예측할 때 1 lag 는 목요일 2 lag 는 수요일 3 lag 는 화요일을 의미한다.
[result 1: Pearson corrleation analysis]

위 Pearson corrleation table 은 아래와 같은 결과를 나타낸다:
1. 트위터 데이터들은 emotionality 를 제외하고 유의미하게 연관성이 있다. Sentiment & Complexity 는 하루 전날 데이터에서 가장 유의미하게 나타나고, 트윗 갯수는 3일차 데이터에서 가장 높은 연관성을 보인다. 만약 트윗 숫자와 complexity 가 낮고 sentiment 가 높다는 것은 다음날 유가가 오를 시그널로 볼 수 있다.
2. Google Trends 와 Wikipedia 둘 다 유의미하게 유가와 연관 돼 있다.
3. GDELT 의 article 의 갯수는 organization 의 갯수보다 훨신 더 높은 연관성을 가지고 있다. ( # of article > # of organizations) Article 갯수는 근소한 차이지만 2일 전날 가장 유의미하게 연관성을 나타낸다.
4. 마지막으로, NASDAQ index 는 유가와 negative correlation 을 보인다. 하지만 이는 유가는 유가 자체랑 연관성을 나타낸단 것이지, 나스닥이 떨어질때 오른다고 보기에는 어렵다. ( 나스닥은 꾸준히 우상향 하였고, 유가는 그렇지 않았기 때문)
[result 2: Granger causality test]
* 시계열에서 one time series 가 결과를 예측하는데 유용한지 알아보는 테스트.
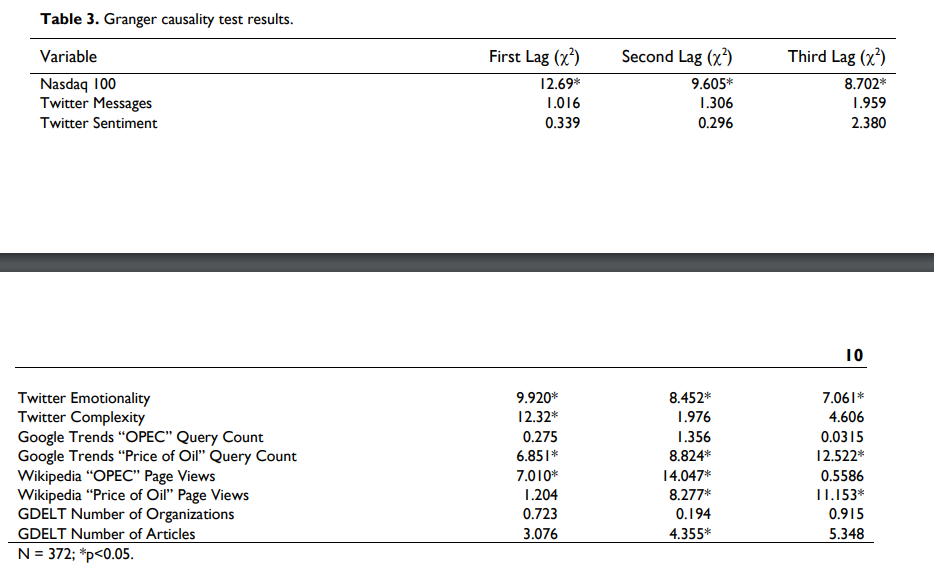
위 테이블은 트위터 Emotionality and Complexity, Google Trends, Wikipedia page view counts, GDELT article 갯수가 유의미한 연관성을 보인다. 트위터 complexity 는 첫날 전에 가장 유의미하게 연관성을 나타낸다. 이 말은, 기술적으로 뛰어나고 유가에 특화된 트레이더들은 하루 전날에 유가 하락을 예측할 수 있다는 말이 될수도 있다.
테이블 3에서부터 시작하여, 여러 변수를 가진 ARIMAX 모델을 사용하여 유가를 예측해보자.
ARIMA 모델은 ARIMA(2,1,4) 모델이 가장 좋은 결과를 보였다. 데이터를 stationary 하게 만들기 위해서 한번 differencing 을 하고 Dicky Fuller unit root test 를 진행하여 stationary data를 확인 후 test하였다.
하지만, ARIMAX 모델은 ARIMA 모델을 outperform 하였다. (RMSE of ARIMA / MAPE of ARIMA: 13.878 / 22.579 , MSE of ARIMAX / MAPE of ARIMAX: 1.683/ 2.498)


<결론>
ARIMAX 모델을 이용하여 유의미하게 유가를 예측할 수 있다. 위 방법은 ARIMA 를 이용해서 유가를 예측할 때 보다 더 뛰어난 모델 성능을 보인다. 모든 위의 요소들을 종합해 볼때 기사 수가 적고, 위키피디아 조회수가 오르며, 트위터에서 simpler language 로 작성될때 유가가 오른다고 예측할 수 있다. 트위터는 하루 단위에서 가장 정확하고, GDELT와 Wikipedia 는 2일, 구글 트렌드는 3일 간격이 가장 유의미하게 예측이 가능하다.
이 실험은 몇가지 한계점이 있다. 수집된 데이터는 키워드 안에서 한정되있는 것들이였다. 그리하여 같은 의미를 가지지만 다른 키워드를 가진것들이 배제 됐을수 있다. 인플루언서나 많은 팔로워를 보유한 사람의 트윗에 대해서 skewed될 수 있다.
출저: https://arxiv.org/pdf/2105.09154.pdf
'3. 심화 학습 (Advanced Topics) > 연구실' 카테고리의 다른 글
| 간단한 BERT 모델을 이용하여 GPT 챗봇 성능 높이기 (1) | 2023.11.23 |
|---|---|
| [논문분석] 딥러닝을 이용하여 불규칙적인 시계열 예측 모델 만들기 (LSTNet) (0) | 2023.01.17 |
| 시계열 분석에서 예측 모델의 구축 및 Stacking을 위한 베이지안 회귀 분석 방법 (2/2) - 구현 (0) | 2022.02.28 |
| 시계열 분석에서 예측 모델의 구축 및 Stacking을 위한 베이지안 회귀 분석 방법 (1/2) - 설명 (0) | 2022.02.16 |
| ARIMAX를 이용하여 미국시장 전망 예측 <작성중> (0) | 2021.08.11 |




댓글